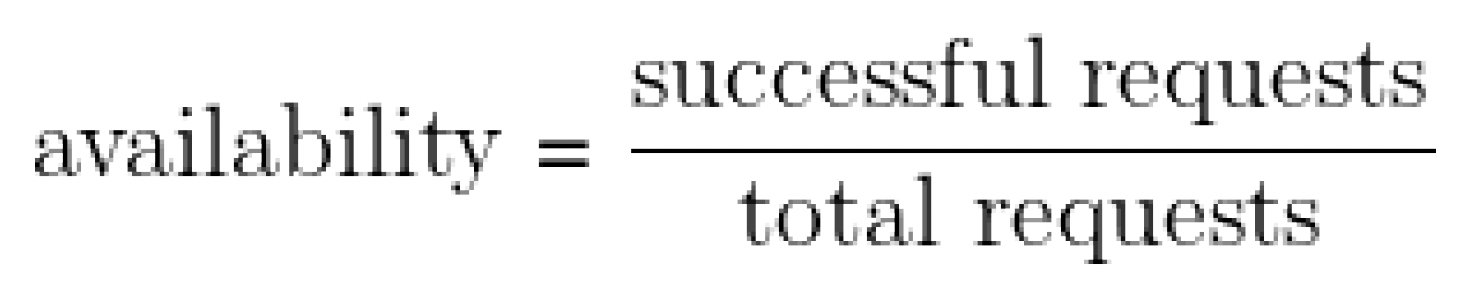Introduction:
The introduction of the book provides an overview of the role of a software engineering manager, and the skills and qualities needed to excel in this role. The author emphasizes that software engineering managers must be effective communicators, strategic thinkers, and leaders, with the ability to work collaboratively with their team members, stakeholders, and other departments within the organization.
Part 1: Building and Managing a Team
The first section of the book, “Building and Managing a Team,” focuses on the importance of building and managing a high-performing software development team. The author emphasizes that technical skills alone are not enough for a successful team, and that team culture, communication, and leadership are equally important.
The section begins with a chapter on hiring, where the author provides practical advice on how to attract the best talent and build a diverse team. He discusses the importance of developing job descriptions, creating effective interview questions, and evaluating candidates based on their skills, experience, and cultural fit.
The following chapters focus on team culture and performance management. The author explains how to create a positive team culture that fosters collaboration, innovation, and a sense of ownership among team members. He also provides guidance on how to manage team performance effectively, including how to set goals, provide feedback, and conduct performance evaluations.
The section concludes with a chapter on coaching, where the author explains how to coach team members to improve their skills, identify and overcome obstacles, and take ownership of their work. He provides practical advice on how to provide constructive feedback, set development goals, and help team members grow professionally.
Part 2: Project Management
The second section of the book, “Project Management,” focuses on the importance of effective project management in software development. The author emphasizes that effective project management is key to delivering high-quality software products on time and within budget.
The section begins with a chapter on project planning, where the author explains how to plan software development projects, including how to identify project goals, create a project plan, and develop a project schedule. He also provides guidance on how to manage project scope, identify and manage risks, and create a project budget.
The following chapters focus on agile methodologies, including how to use agile methodologies to manage software development projects effectively, how to tailor agile processes to fit the needs of the team and the project, and how to facilitate effective team meetings, stand-ups, and retrospectives.
The section concludes with a chapter on stakeholder management, where the author emphasizes the importance of effective communication with stakeholders, including how to identify stakeholders, establish communication channels, and manage stakeholder expectations.
Part 3: Personal Growth and Development
The final section of the book, “Personal Growth and Development,” focuses on the importance of continuous learning and development as a software engineering manager. The author emphasizes that staying up-to-date with the latest trends and technologies in software engineering is essential to being an effective manager.
The section begins with a chapter on time management, where the author provides practical advice on how to manage time effectively, including how to prioritize tasks, set realistic deadlines, and avoid distractions.
The following chapters focus on personal development, including how to set goals, identify areas for improvement, and seek feedback from team members and stakeholders. The author explains how to use feedback to develop new skills, improve performance, and enhance personal growth.
The section concludes with a chapter on work-life balance, where the author emphasizes the importance of maintaining a healthy work-life balance, including how to set boundaries, manage stress, and prioritize personal well-being.
Conclusion:
The conclusion of the book summarizes the key takeaways from each section, and emphasizes the importance of ongoing learning and growth in the software engineering management field. The author encourages readers to apply the principles and techniques presented in the book to their own work as software engineering managers, and to adapt them to fit the needs of their teams and organizations.
Overall, “Becoming an Effective Software Engineering Manager” provides a comprehensive guide to building and managing high-performing software development teams, managing software development projects effectively, and continuously developing personal and professional skills. The book is highly practical, with numerous real-world examples and case studies, and provides actionable advice that readers can apply immediately in their own work as software engineering managers.
One of the strengths of the book is its emphasis on the importance of communication and collaboration in software development. The author provides practical advice on how to build a positive team culture, facilitate effective team meetings, and manage stakeholder relationships, all of which are essential to delivering high-quality software products on time and within budget.
Another strength of the book is its focus on personal development. The author emphasizes the importance of continuous learning and growth as a software engineering manager, and provides practical advice on how to manage time effectively, set goals, seek feedback, and maintain a healthy work-life balance.
Overall, “Becoming an Effective Software Engineering Manager” is a must-read for anyone who is interested in building and managing high-performing software development teams. The book provides practical, actionable advice that readers can apply immediately in their own work, and emphasizes the importance of ongoing learning and growth in the software engineering management field.